Tomorrow I have to go into Boston to meet with two of my professors. One of them is my advisor, and the other is actually the head of my graduate program. The deal is, I owe them both work. I’m feeling a little like my debts are being called in. I’m not sure what the consequences will be if I don’t make good. I can’t see them sending someone out to rough me up…
I know that they mean this to be a way to help me move forward with my studies and career-related work. Things have been a bit slower in that area for the past 10 months or so due to an increase in my family size. However, I have not been completely inactive in this area. And I have not been otherwise on vacation. (Actually, I feel ready for a vacation right about now.) However, I still must justify my existence as a grad student by giving a report on two projects that I owe.
Debt One:
My incomplete. Or really, I should say My Incomplete. Incompletes are not things to be undertaken lightly. It seems so harmless to ask for a bit of extra time. But this is all an illusion. I knew that going in. I’d had an incomplete before, and it haunted my dreams for over a year before I managed to tackle that monster. This one was only supposed to lead to a delay of a few weeks. A month or two at most. But the class ended last December. And BUreaucracy dictates that I must finish within a year.
Once upon a time, sometime in early to mid December of last year, I was almost finished with this paper for my Field Methods class. I was working on the topic of intonation. Things were going well. Progress was being made. I was enjoying getting into the data. Then, out of the blue, inconvenience struck. Struck me down. It was actually a pregnancy-related thing, involving pointless and very time-consuming medical tests. And more detrimental to my progress, a whole lot of distracting irritation with the whole process. It only set me back a couple of days, but at a time that I didn’t have a couple of extra days to spare due to other work deadlines rapidly encroaching. So I made that fatal step and asked for the incomplete. I estimated I could finish the paper in about 8 hours. The plan was to get back to it in January or February. January flew by in a rush of very exciting work. And when February hit, I was as big as a house. And apparently never managed to muster up the necessary motivation. Sigh.
Now many moons have passed, and it will take me more than 8 hours to finish. Because I must refamiliarize myself with all of it. And probably redecide what I want to say. But here’s what I have for data:
- 224 .wav format soundfiles of short utterances of Palestinian Arabic produced by a native speaker. They consist of single words, short phrases, short sentences and a few longer sentences and utterances. These include questions and declaratives with varying focus patterns.
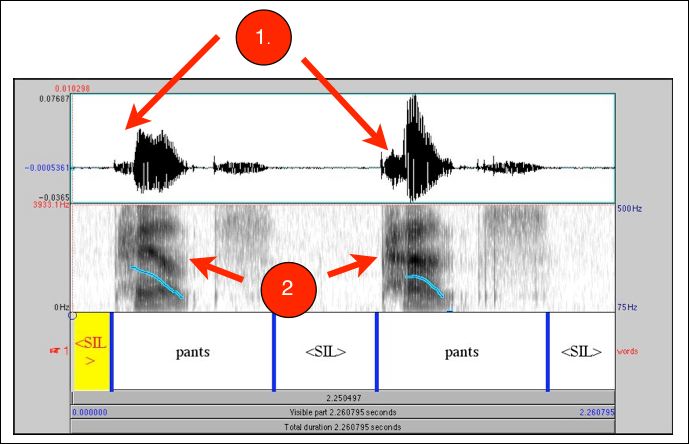
- All have been labelled in Praat, using TextGrids with time-aligned labels for intonation (using ToBI-based labels), broad IPA transcription, word-by-word glosses, and translation. Some files have additional comments.
- I’ve made a small, simple Filemaker database of the files and labels so far, with codings for type of utterance and context.
I have a very rough outline of the paper, which includes a bit of background, some dicussion points, and some pretty pictures of a few examples, but not yet any description/discussion of those examples (or even examples for many of the types I’d like to discuss.) I have an additional partially labelled eliciation session with the native speaker which contains cool data that I hate to entirely leave out. I’d like to finish labelling and coding it. (However, I think this may be something I’ll have to forego.) What I need to do is discuss the examples, fill in the background section, and summarize my findings. (Basically, “write the damn paper.”)
Debt Two:
The project I owe my other professor is either a script or a collection of scripts to help process large quantities of data. The plan is to go from a long soundfile (usually about 30 minutes) to a database with details on individual tokens, and short soundfiles of individual utterances. Happily, this is not new territory for me. It’s also a project that I find very appealing. So far, what I have is a collection of scripts, mostly written by other people, that I have started modifying for our nefarious purposes. Right now, there are several Praat scripts (for chopping big files, and then for getting acoustic measurements based on TextGrid labels). I also have a Perl script (which I mostly wrote myself!) which collects labels from TextGrid tiers that I have used to dump labels into a Filemaker database for my ToBI-related work. I’m thinking that I may be able to do away the Perl script, once I learn more about Praat scripts. Right now, I haven’t figured out a good way to collect labels from point tiers. Most scripts I’ve seen have made more use of interval tiers. But I figure I’ll find the answer with a bit more digging.
So there it is. Those are (some of) my outstanding debts. I’m hoping the plan for tomorrow is to work out some sort of payment plan. Before the debts are sent to the collection agencies. (Hmm. Another sense of the word collection.)